Introduction
Why On-Premises?
Deploying on-premises offers several advantages over using cloud APIs over a public network. One of the main benefits is speed; by hosting the services locally, you can significantly reduce network latency, resulting in faster system responses and data processing.Security
With an on-premises deployment, all sensitive data remains within your corporate network, ensuring enhanced security as it is not transmitted over the Internet. This setup helps in complying with strict data privacy and protection regulations.Performance
Latency
- Mistv2: Our tests have shown median latency of 175ms with randomly generated sentences between 40 and 50 characters on A10Gs and similar GPUs.
- Arcana: See performance tuning.
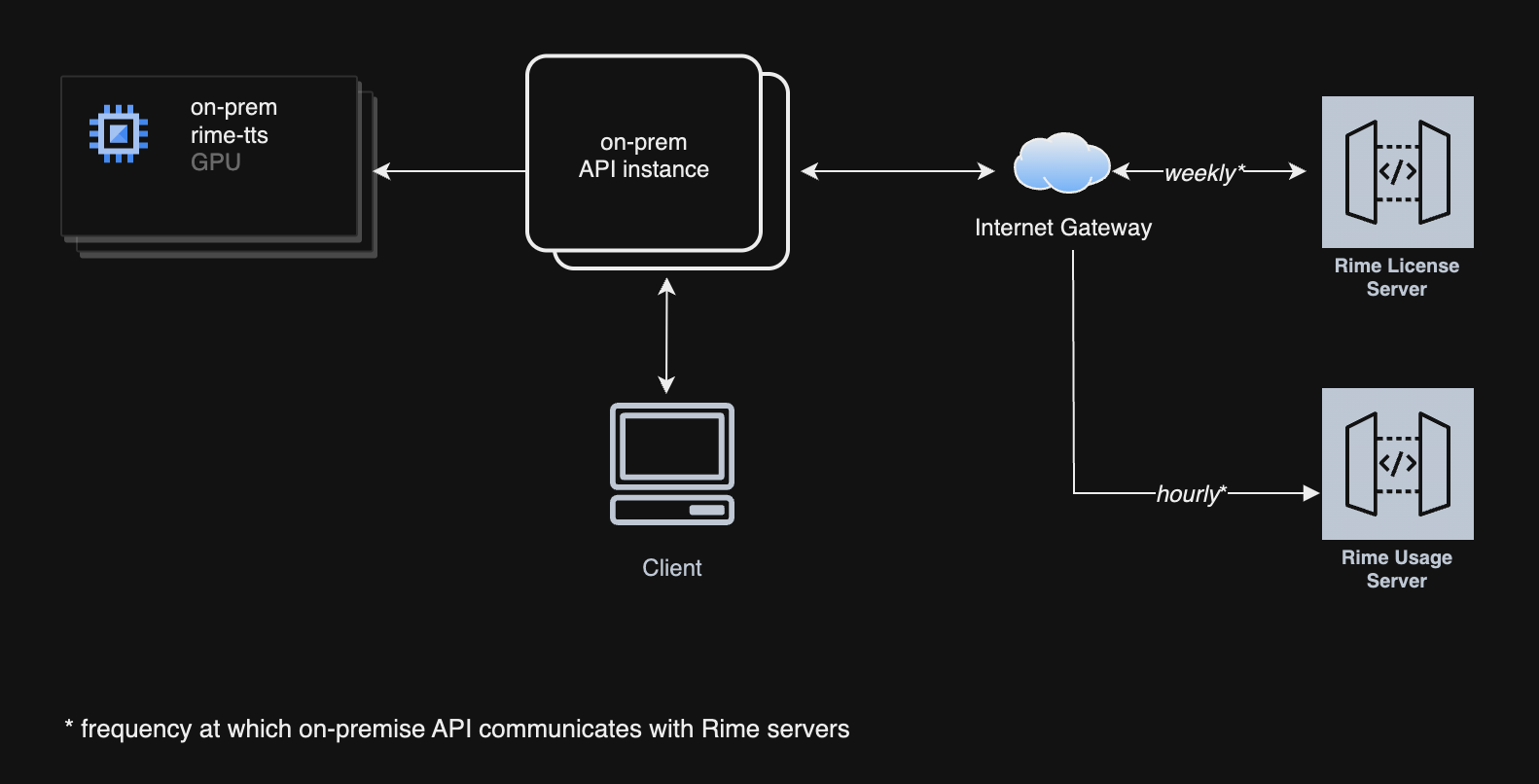
Components
Prerequisites
Hardware Requirements
- GPU
- For Mist
- NVIDIA T4, L4, A10, or higher
- For Arcana
- NVIDIA A100, H100 MIG
3g.40gb, or higher
- NVIDIA A100, H100 MIG
- For Mist
- Storage
- 50 GB storage
- CPU
- 8 vCPUs
- Memory requirements
- 32 GiB
Software Requirements
- Supported Linux Distributions
- Debian 12 (
bookworm), x86_64 - Ubuntu Server 24.04 (
jammy), x86_64
- Debian 12 (
- NVIDIA drivers
- Minimum:
525.60.13 - Recommended:
570.133.20or higher
- Minimum:
- Docker
- NVIDIA Container Toolkit
Installations
NVIDIA Drivers
Follow https://www.nvidia.com/en-us/drivers to install the latest NVIDIA drivers, or use the following instructions on Debian-based systems:NVIDIA Driver Installation (Debian-based)
Docker
Follow https://docs.docker.com/engine/install to install Docker on your system. Optionally, add the current user to thedocker group for convenience: https://docs.docker.com/engine/install/linux-postinstall.
The code snippets below assume that you can run docker as the current login.
NVIDIA Container Toolkit
Follow https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html to install the NVIDIA Container Toolkit. Note that you should follow both the Installation and the Configuration sections.Verification
To verify that you have all the prerequisites installed, run the following command:Verify Prerequisites
Firewall Requirements
The Rime API instance will listen on port8000 for http traffic, and port 8001 for websockets traffic.
You will also need to allow the following outbound traffic in your firewall rules:
https://optimize.rime.ai/usage: registers on-prem usage with our servers.https://optimize.rime.ai/license: verifies that your on-prem license is active.us-docker.pkg.devon port443: container image registry.
Self-Service Licensing & Credentials
API Key Generation
Refer to our user interface dashboard to generate the necessary keys and credentials for authenticating and authorizing the deployment and use of our services.Deployment
The deployment consists of two services, each powered by a container image:- API service: responsible for handling the HTTP and WebSocket requests, and for verifying the license. It serves as a proxy to the TTS service.
- TTS service: responsible for model inference.
Artifact Registry Login
Key file to be provided by Rime.Login to Artifact Registry
Container Images
TTS Service
Arcana
The Arcana images can be found atus-docker.pkg.dev/rime-labs/arcana/v2/<language>:<tag>.
- The support languages are:
ar,de,en,es,fr,hi,si. - The latest version is
20260122.
us-docker.pkg.dev/rime-labs/engine/arcana:<tag>us-docker.pkg.dev/rime-labs/package/arcana/<language>:<tag>
Mist
There is only a mist on-prem image for English:us-docker.pkg.dev/rime-labs/mist/v2/en:20251106
API Service
The latest image version is:us-docker.pkg.dev/rime-labs/api/service:20251209
Docker Compose Configuration
A simple way of deploying on a machine is to use Docker Compose. Create acompose.yml file with your editor of choice to define the services and their configurations:
compose.yml
When running on Kubernetes, ensure thatMODEL_URLpoints tohttp://0.0.0.0:8080/invocationsinstead of the Docker Compose service name.
Multi-model backend
If you want to serve multiple arcana language via a single API instance, you can create acompose.yml like the following:
compose.yml
ARCANA_{LANG}_MODEL_URL env var must point to the container running the arcana image for that language,
but you should still point MODEL_URL to a default model container. The model env vars currently supported are:
Start Docker Compose
Start Docker Compose
Deployment Steps
- Environment Setup: Prepare your AWS environment according to the specifications required for optimal deployment.
- Service Deployment: Using Docker, deploy the images on your server.
- Networking Setup: Configure the network settings, including the Internet Gateway and port settings, to ensure connectivity and security.
- Licensing and Authentication: Generate and apply the necessary API key via our dashboard to start using the services.
Note: Once the containers are started, expect 5 minutes delay for warm up before sending first tts requests.
Additional Information
- Troubleshooting Guide: A troubleshooting guide will be provided to help resolve common issues during deployment.
- Available voices/models: all voices are currently available.
Requests and Response Formats
HTTP Requests
Request:Health Check
Request Example
Response Format
Receiving a response in mp3 format
Request:Request Example
Receiving a response in pcm (raw) format
Request:Request Example
Websockets Endpoints
The json websockets endpoint will be served at port8001. For example ws://localhost:8001 which will be equivalent to our cloud websockets-json API.