tl;dr: Rime is really fast.
Sub-200ms latency is standard; contact us to optimize further.
On-premises deployments are available and have sub-100ms latency.
TTS and latency
The response time from any text-to-speech (TTS) API depends on a variety of factors, including network latency, the length of the text input, any text preprocessing needed prior to model inference, and payload size.
Rime’s TTS API has been designed from the ground up to be the fastest to respond. The following sections will have information on the contributing factors to response latency and recommendations for reducing this latency.
Factors that affect API response time
- Inference time: In general, server processing time will include the amount of time that the server takes to process the API request; for deep-learning TTS models, this will include model inference time but also text preprocessing functions and audio postprocessing.
- Payload size: The size of the response data sent between the server and the client can impact API response time — large payloads take longer to transmit across the network.
- Network latency: Network latency affects response time due to the simple fact that distance from the server will increase the amount of time it takes for the payload to get to the client.
Streaming
Assuming the client is able to stream audio, whether on-device or through a telephony provider or system, streaming will always be faster than non-streaming requests to our API. The reason for this is simple: a great deal of end-to-end response time comes down to the client. If we reduce the size of the initial payload chunk, we can reduce TTFB, which is the time audio can start streaming.
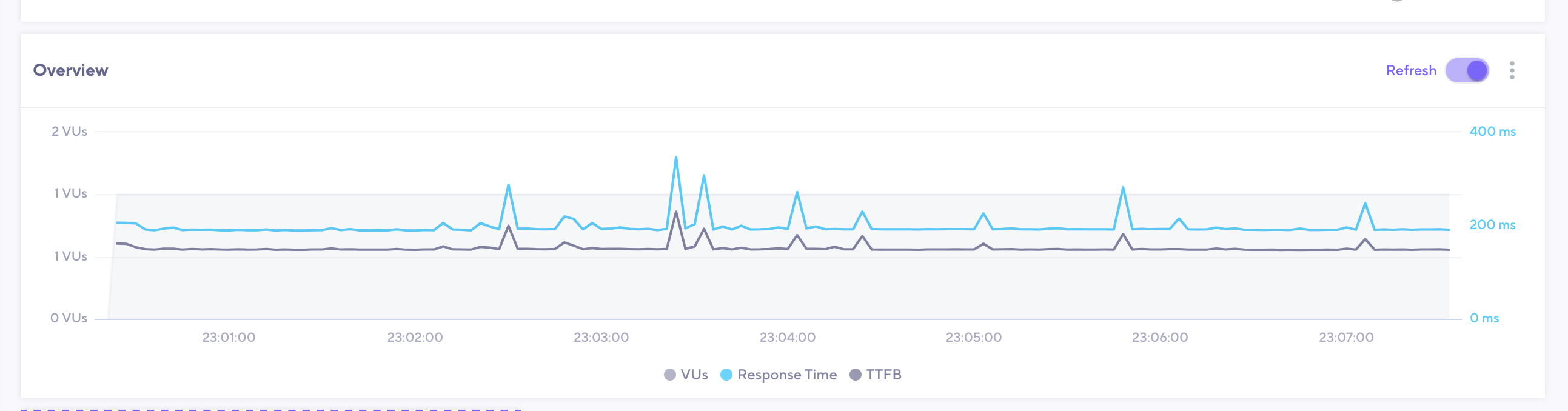
The image above contains a plot of both response time and TTFB for the following request body to our streaming PCM endpoint:
curl -X POST http://users.rime.ai/v1/rime-tts \
-H 'Accept: audio/pcm' \
-H 'Authorization: Bearer $RIME_API_KEY' \
-d '{"text": "I love the book that she gave me. And I was so happy that she gave it to me.", "speaker": "juan", "modelId": "mistv2"}'
Recommendations for reducing response time
Rime’s mistv2 and mist models are across the board faster than our v1 models (which were deprecated in February 2025). Using the modelId parameter, you can select our Mist models for TTS inference.
- Use the API parameter
noTextNormalization, which turns off text normalization, to reduce the amount of computation needed to prepare input text for TTS inference. This can safely be used in cases where there are no digits, abbreviations, or tricky punctuation, such as in Yes, I grew up on one twenty-three Main Street in Oakland, California. instead of Yes, I grew up on 123 Main St. in Oakland, CA..
- Request audio that meets the needs of your application. Remember: Smaller payloads move across the network more quickly. For example, if you’re building an application for telephony, request 8000kHz-sampled audio using the
samplingRate parameter.
Rime’s models produce PCM audio by default, and conversion and downsampling must take place for sampling rates other than 22kHz. Still, the reduction in payload size and therefore network overhead more than makes up for increased server processing time.